在当今数据驱动的世界中,多模态数据已经成为企业的重要资产。随着数据规模和多样性的不断增加,企业不仅需要高效存储和处理这些数据,更需要从中提取有价值的洞察。工业领域在处理海量设备时序数据的同时,还需要联动分析警报信息、设备关系、组织信息等关系数据或图数据;金融领域除了常见的行情和订单流时序数据外,还会采用地理信息、实时新闻、气象数据等多种类型的数据辅助决策。然而,要充分挖掘和利用这些多模态数据,传统单一模型的时序数据库已显得力不从心,无法满足现代多元应用场景中企业对数据使用的复杂需求。
Transwarp TimeLyre是星环科技自主研发的企业级分布式时序数据库,具备高吞吐实时写入、时序精准查询、超高数据压缩率等特点,可以支持海量时序数据的存储、查询、分析,有效支撑能源、制造、金融领域等多种时序数据业务场景。
近日,TimeLyre正式发布V9.2版本,支持海量时序数据的同时,具备原生的多模态数据混合存储能力,能够整合和处理不同类型的数据,帮助企业实现数据的多维分析。同时提供高性能分析、热温冷数据分层存储、极速时序数据回放分析等新功能,可以有效支撑大规模时序数据湖、投研一体化平台、时序数据中台等新场景,充分满足企业对多模态数据存储分析的需求,助力企业发挥数据深层价值。
原生多模态架构,支持时序数据与关系数据模型混合存储
TimeLyreV9.2采用原生多模态架构,来自多种数据源的时序和关系数据经由统一的接口以批量或实时的方式存入统一的存储引擎中,通过统一的高性能计算引擎Quark进行读取和分析,支撑上层模型加工、批处理、在线分析、高性能读取等场景,助力企业更全面、更多维度的数据分析应用。
不同于传统方案为不同类型的数据单独部署和使用不同的数据库产品,TimeLyre以原生的多模态架构高效实现了多种数据模型的转化流转与关联分析,具有复杂度低、开发和运维成本低、数据处理效率高等优势。

高性能C++计算引擎,向量化计算,显著提升数据分析性能
依托于星环科技统一的多模型数据管理平台架构,TimeLyre在计算引擎中纳入了高性能C++计算引擎技术,通过使用向量化计算,充分利用了现代CPU的SIMD指令集,借助列式扫描减少了IO开销。同时采用高性能数据传输格式,实现了数据零拷贝,减少了序列化和反序列化的开销,并借助列式存储和高压缩率,减少了网络传输的数据量,便于数据更快速地接入高性能C++分析引擎。通过采用高性能分析计算引擎,可以帮助用户显著提高数据处理能力和效率,更快获取分析结果,加速决策过程,降低能耗和硬件成本,帮助用户在数据驱动的商业环境中保持领先。
热温冷数据自动分层存储,降低存储成本,优化资源配置
TimeLyre提供全新的热温冷数据分层存储方案,统一接收外部应用的数据写入和数据查询,内部按时间或指定条件将热数据、温数据和冷数据进行自动转换。对于热数据,可以实现毫秒级查询性能,提供5倍以上数据压缩率;温数据支持百毫秒查询性能,提供15倍以上压缩率;冷数据提供30倍以上数据压缩率,满足数据批量加工需求。热温冷数据的分层仅需在建表时通过DDL指定,无需后期运维,即可实现定期后台自动分层。同时支持指定数据存储在不同的存储介质上,进一步降低综合存储成本,优化资源配置。
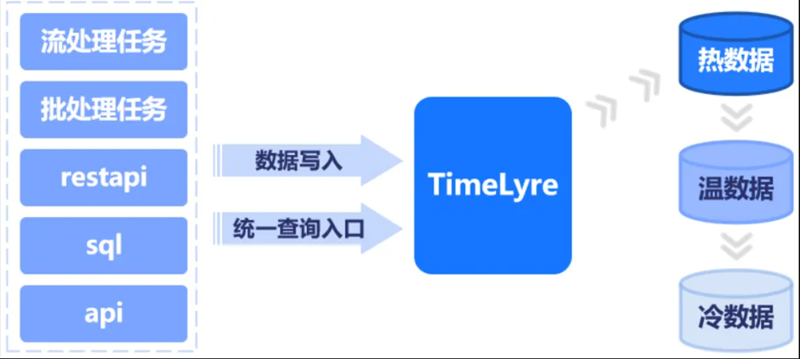
支撑分布式极速时序回放分析引擎TransMatrix,助力时序数据回放分析
TransMatrix是星环研发的分布式投研系统,用户可以将多种数据结构、多种频率(高、中、低频)的数据按照时间顺序进行回访;支持原生多模态数据源回放,可以从星环TDH中直接读取和加工数据源,除了时序和关系数据之外,还支持文本数据、图数据、图片数据等,同时允许用户借助Python开源生态对多模态数据进行加工和分析;内置丰富的时序算子库,支持自定义算子开发与共享;采用事件驱动的编程范式,提供生成式算子开发接口;提供算子拼接接口与丰富的内置表达式,支持用户自定义表达式;通过分布式任务实现多租户负载均衡、提供分布式任务配置接口,可实现任务拆分、批量运行、大规模采样等大型任务。
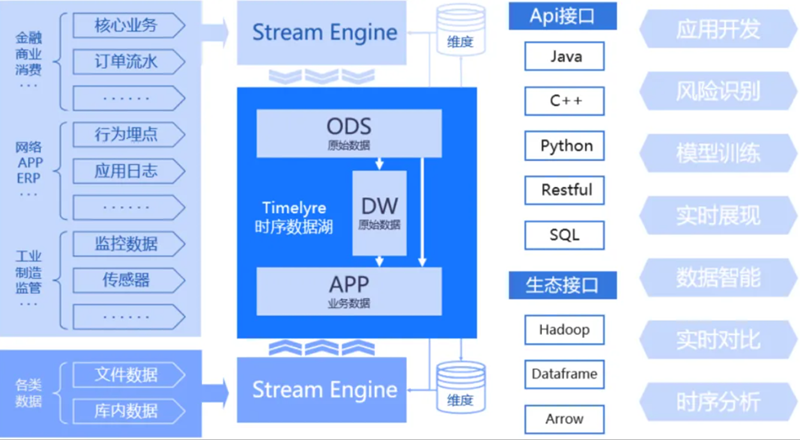
新场景:大规模时序数据湖引擎,助力企业应对海量时序数据
用户可以基于TimeLyre构建大规模时序数据湖,海量时序数据通过流式引擎进入数据湖内,依托TimeLyre完成ODS层、DW层、维度层数据加载与处理,通过丰富的API接口和开源生态接口支撑上层应用开发、风险识别、模型训练、实时展示、数据智能、时序分析等业务场景。以TimeLyre为核心构建时序数据湖,充分利用了产品对海量实时数据的存储与查询分析能力,实时写入性能可达每节点千万测点,实时查询性能可达每节点10000QPS。结合流、批计算引擎,满足业务对端到端秒级时效性的要求。同时支持时序数据与关系数据高效关联分析、提供完善的SQL支持与灵活可变的Schema定义,为用户提供全面、高效、灵活的数据管理分析平台。
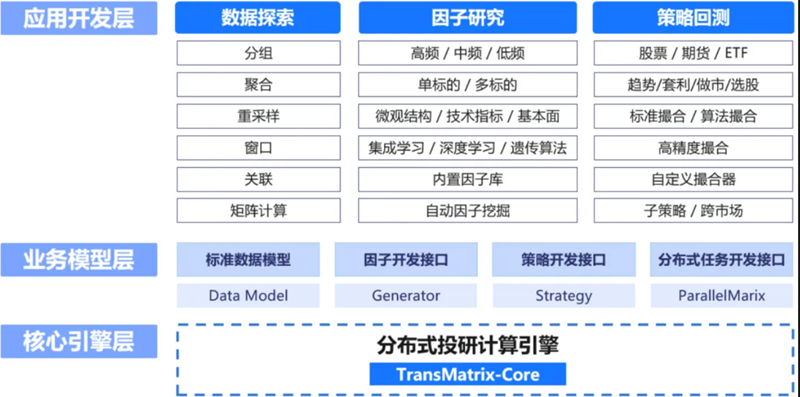
新场景:投研一体化平台技术底座,搭建分布式投研框架
面向金融投研场景,TimeLyre可以作为投研一体化平台的技术底座,助力企业搭建分布式投研框架。底层依托时序数据库TimeLyre及其内置的分布式投研计算引擎TransMatrix构建投研平台核心技术底座,通过标准数据接口、因子开发接口、策略开发接口和分布式任务开发接口对接上层业务模型,助力企业在一体化平台内实现数据泰索、因子研究、策略回测等应用开发。
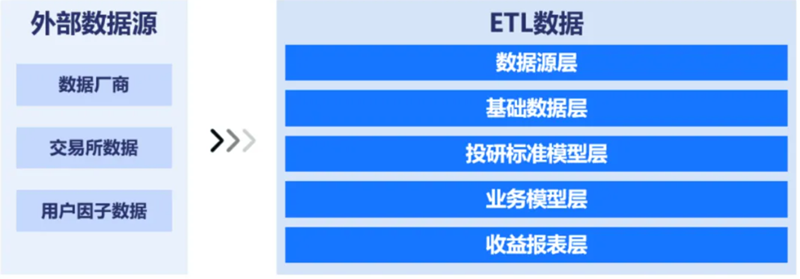
新场景:投研数据中台数据底座,实现多源数据分层管理
依托TimeLyre构建投研数据中台,参考标准数据分层结构,可将数据分为数据源层、基础数据层、投研标准层、业务模型层与收益报表层。在数据源层负责从数据厂商、交易所数据、用户因子数据等外部数据源同步数据,可以做到将原始的行情或因子数据以完全一致的形式同步入投研数据中台;基础数据层负责完成数据的校验、清洗与加工,生成干净的基础投研数据;投研标准层负责将这些数据统一成面向投研过程的标准表模型以及数据结构模型,为用户屏蔽掉不同来源数据在字段名、字段类型等方面的差异;业务模型层负责生成面向特定研究过程的因子与数据;收益报表层负责生成面向投研收益评价的因子与数据,可以将策略的研究结果、投研结果以报表的形式存在时序模型或关系模型中。
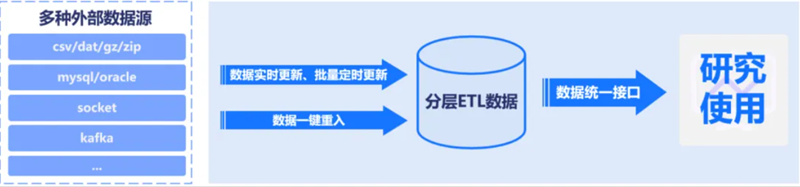
依托TimeLyre构建投研数据中台可以对接丰富的外部数据源,实现多层次外部数据录入,支持以投研领域常见的文件形式加载数据、从主流数据库(MySQL、Oracle等)进行数据同步、通过类似SQL的API接收交易所实时行情、通过Kafka统一接受数据等多种数据接入方式。同时为了应对数据实时和批量更新的需求,提供专业的ETL工具,可以实现数据的一键重入,开启一键重入即可自动触发多层次数据加工,实现投研数据的自动更新,并通过统一的API提供给业务人员进行研究使用。
赋能业务:TimeLyre助力某光伏企业打造批流一体时序数据湖方案
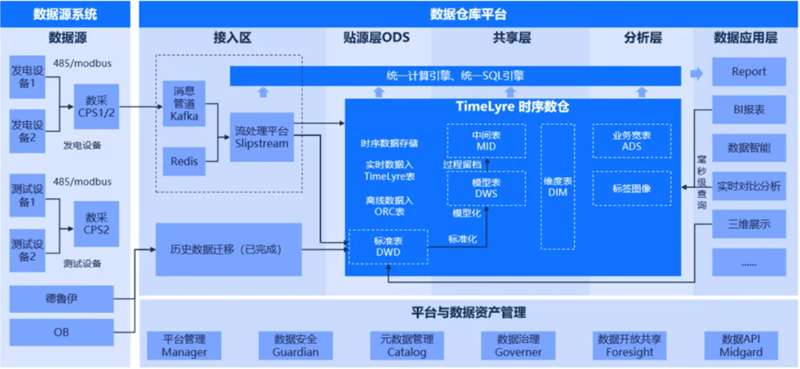
某光伏企业为解决数据孤岛问题,依托星环科技分布式时序数据库TimeLyre构建批流一体的时序数据湖。首先通过数采设备从数据源系统中获取原始数据,统一经由Kafka消息系统汇入数仓平台的数据接入区,并通过TimeLyre自带的流处理引擎Slipstream将数据加载到内部的贴源层,实现时序数据、关系数据等多模态数据的统一存储。数仓内部通过统一的计算引擎和SQL引擎将数据加工到不同的层次,包括标准表DWD层、中间表MID层、模型表DWS层、维度表DIM层和业务宽表ADS层等,用以支撑上层业务报告、BI报表、数据智能、实时分析对比、三维展示等应用场景。值得注意的是数仓平台以TimeLyre为核心,仅通过TimeLyre一个数据库,就实现了时序数据、关系数据从贴源层到应用层的加工、分析和查询。
项目基于星环大数据技术实现了光伏数据的统一接入,包括设备测点数据的实时接入以及管理数据、巡检图片、运行日志等数据的全量接入,目前已实现基地3300多台设备、近30万测点数据的秒级入库。并且方案具备水平扩展能力,未来增加硬件资源,也可顺利接入新建场站数据。
同时依托星环科技时序数据库、批处理引擎和分析库构建的光伏数据底座,可以实现各类数据的存储和数仓模型加工,通过统一的计算引擎和统一的数据接口,支撑各类可视化数据应用的构建,方便光伏实验实证分析人员利用大数据技术开展数据对比分析、设备性能查询、运行曲线查看等日常工作。
此外基于星环一体化平台与数据资产管理,实现了全平台数据的统一授权、开发、治理、开放、审计,让各部门的开发人员,可以快速便利的获得所需的数据资源,并基于高性能的时序数据湖平台进行数据分析。



